# Overview
## Alluxio Edge Overview
Alluxio Edge is a lightweight fast data access caching library for Trino and PrestoDB.
### Challenge
As the data ecosystem evolves over the last 10 years, we have seen the trend moving away from the tightly coupled MapReduce and HDFS bundle into the compute / storage separation model. With the rise of Kubernetes and containerized applications, we see all the advantages of elasticity, ease of management, and scalability.
However, one major downside that comes with that is the loss of data locality. Especially when the data goes onto cloud, or a remote region, even as fast as light travels, it takes extra time compared to if data just sits right by the compute-engine on the same node. This is why we introduced Alluxio Edge to solve these challenges.
### What is Alluxio Edge
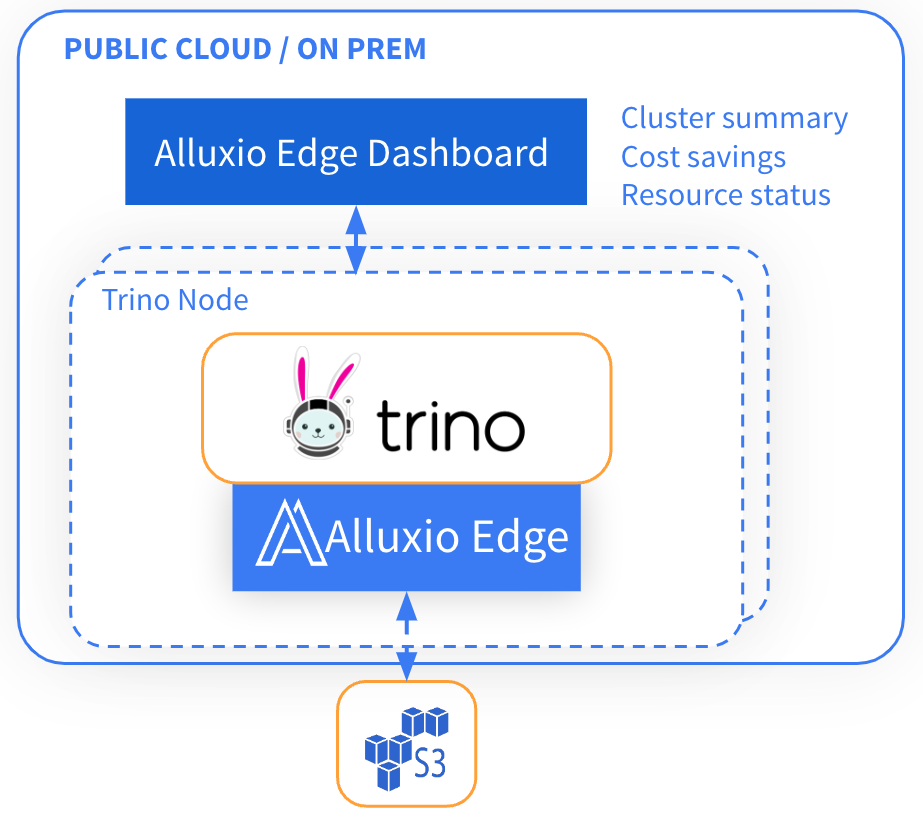
Alluxio Edge is a lightweight fast data access caching layer for Trino and PrestoDB. Using Trino for example, we can run Alluxio Edge as a library in the existing Trino process. Alluxio Edge will take over the I/O path for Trino queries and serve the data to Trino. Instead of every metadata or data request goes to S3 (or other remote storages), the majority of it will go through Alluxio and only fetch from S3 when necessary. This way Alluxio Edge not only helps to speed up the queries by taking advantage of locality but also saves the request and data egress cost from S3.
On top of that, a dashboard is also provided for user convenience. It provides insights of the data pattern: cache hit count and ratio on the requests or data, in addition to resource status and cluster summary.
### How Does Alluxio Edge Work - A Deeper Dive
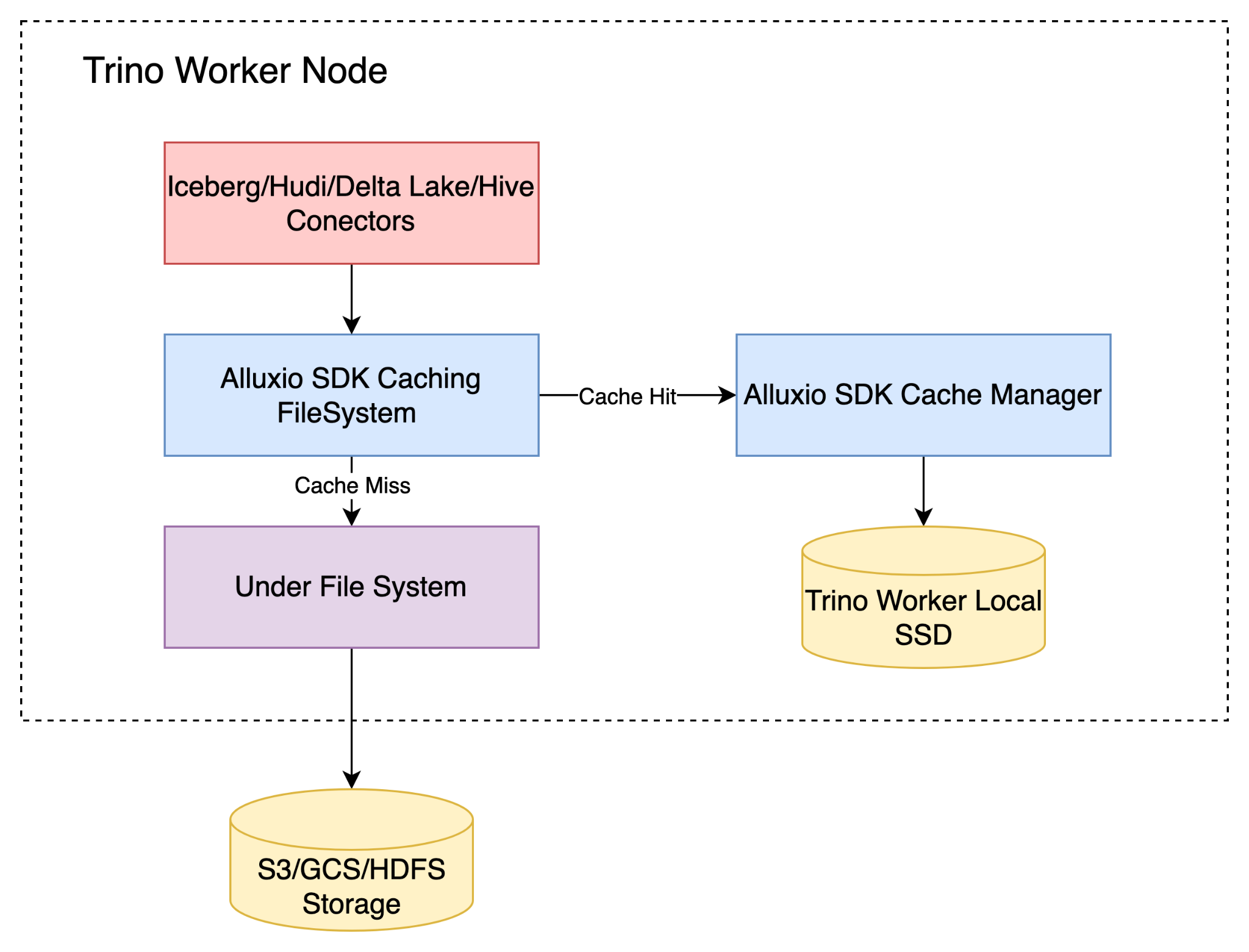
Alluxio Edge introduces a transformative approach by revamping the implementation of the data access interface. At the core of this innovation is the addition of a local cache layer. Alluxio Edge utilizes the local cache layer and takes over all data retrieval operations to optimize data access. When a data access request is initiated, the system first examines this local cache. If the requested data is available in the cache (a cache hit), it is swiftly loaded from there, thereby significantly reducing access times and enhancing overall system performance. In cases where the cache does not contain the requested data, the system then defaults to retrieving data from the underlying storage, be it HDFS or S3. This intelligent caching mechanism, therefore, ensures a more efficient, faster data processing workflow, bolstering the capabilities of Trino/PrestoDB in handling large-scale data operations.
### How Can it Help Your Business
#### Use Case 1: Performance Boost by Bringing Data Local
Alluxio Edge optimizes I/O to achieve local query latency on remote data lakes. Alluxio Edge can significantly improve the performance of queries by bringing hot data locality with the compute node.
In one of our user examples, we see 40% performance improvement for Trino queries. On one hand, this performance gain directly cuts down the end user’s query wait time. On the other hand, from the whole infra point of view, even after increasing Trino traffic by 20%, they were still able to free up 30% compute capacity and give that to other workloads.
#### Use Case 2: Cloud Cost Slasher
When the majority of the request and data serving goes through Alluxio Edge, the cloud transfer cost can be reduced in proportion to the cache hit ratio of the request and data. This is a very straightforward cost saving benefit from Alluxio.
In one of the user example, we see that up to 80% reduction of the number of read requests to the cloud, and in their scale of 1500 nodes, 500k query/day, 90PB data read/day, that translates to as much as $10-20 million/year in cloud cost savings.
#### Use Case 3: Under-storages Stabilization
When Alluxio Edge is in the middle, the under-storage gets a big relief in terms of load and network congestion. This helps to stabilize some frequently overwhelmed storages like HDFS. Although this is hard to measure in terms of direct cost, we have seen it well received from HDFS teams.