# 文件读取
本文档介绍了Alluxio的部分功能,可提高部分场景下的Alluxio性能。
## Client 异步预取
如果当前文件正在进行顺序读,Alluxio client 会在当前读取位置后预取一定范围的数据,并开始在client 上缓存这些数据。 如果当前读取位置的数据已经被预取缓存,Alluxio client 将返回缓存数据,而不是向 Worker 发送 RPC 请求。
预取窗口是自调节的。 如果读取总是从上次读取位置的末尾开始(即读取连续),预取窗口将增大。 如果读取不连续,预取窗口会缩小。 如果读取完全是随机读取,预取窗口最终会缩小为 0。
异步预取将数据缓存到 client 的直接内存中。 通过增加分配给 JVM 进程的直接内存,可提高性能。
Client 异步预取始终处于启用状态。 用户可通过以下参数来调整此功能。
| 配置项 | 推荐值 | 描述 |
| --------------------------------------------------------------------------- | --- | ------------------------------------------------------------------------ |
| alluxio.user.position.reader.streaming.async.prefetch.thread | 64 | 总异步预取并发数 |
| alluxio.user.position.reader.streaming.async.prefetch.part.length | 4MB | 预取单元的大小 |
| alluxio.user.position.reader.streaming.async.prefetch.max.part.number | 8 | 单个已打开文件的最大单元数。 例如,如果预取单元大小为 4MB,最大单元数为 8,则 Alluxio 最多会为打开的文件预取 32MB 的数据。 |
| alluxio.user.position.reader.streaming.async.prefetch.file.length.threshold | 4MB | 如果文件大小小于指定阈值,Alluxio 会立即最大化预取窗口,而不是从一个小窗口开始。 此配置用于提高小文件的读取性能。 |
### 启用慢速异步预取池
用户可能会在不同情况下需要不同的异步预取参数,例如冷读取与缓存过滤读取。
冷读通常需要更多并发量,以最大限度地利用网络带宽并实现最佳性能。 Alluxio 有一个专用于其他配置的辅助异步预取池,称为慢速线程池。 要启用和配置该辅助池,请进行以下配置:
| 配置项 | 推荐值 | 描述 |
| ----------------------------------------------------------------------------------------- | ---- | --------------------------------------- |
| alluxio.user.position.reader.streaming.async.prefetch.use.slow\.thread.pool | true | 设置为 true 可启用慢速池 |
| alluxio.user.position.reader.streaming.async.prefetch.use.slow\.thread.pool.for.cold.read | true | 如果设置为 true,慢速池也将用于冷读取。否则,慢速池将仅用于缓存过滤读取。 |
| alluxio.user.position.reader.streaming.slow\.async.prefetch.thread | 256 | 慢速池的总异步预取并发数 |
| alluxio.user.position.reader.streaming.slow\.async.prefetch.part.length | 1MB | 慢速池使用的预取单元大小 |
| alluxio.user.position.reader.streaming.slow\.async.prefetch.max.part.number | 64 | 单个已打开文件在慢速池中可以拥有的最大单元数 |
### 大文件读取
### 冷读优化
大文件预加载是对大文件冷读的优化。
如果启用该功能,Alluxio 将在 client 最初读取文件时将整个文件同时加载到 Alluxio Worker 中。 在对存储在 S3 上的单个 100GB 文件运行 FIO 基准测试时,在开启该功能后,Alluxio的冷读性能可以接近全缓存的热读性能。
数据去重是在 client 和 worker 端处理的,以避免产生过多的 RPC 调用和向 UFS 传输冗余数据。 请注意,由于 Alluxio 总是加载完整的文件,如果应用程序不需要读取整个文件,此功能可能会导致读放大。
启用该功能,需要做以下配置:
| 配置项 | 推荐值 | 描述 |
| ----------------------------------------------------------------- | ----- | ---------------------------------------------------------------------------------------------------------------- |
| alluxio.user.position.reader.preload.data.enabled | true | 设置为 true 可启用大文件预加载 |
| alluxio.user.position.reader.preload.data.file.size.threshold.min | 1GB | 触发异步预加载的最小文件大小 |
| alluxio.user.position.reader.preload.data.file.size.threshold.max | 200GB | 触发异步预加载的最大文件大小。 这有助于避免加载超大文件,因为超大文件会完全填满页面存储容量并触发缓存驱逐。 |
| alluxio.worker.preload.data.thread.pool.size | 64 | 在 worker 上并行加载文件数据到 UFS 的并发作业数。每个作业会将一页数据加载到 Alluxio 中。 例如,如果页面大小为 4MB, 且该配置设置为 64,则 worker 每次迭代将并发加载 256MB 的数据。 |
### 大文件分片
在 Alluxio 中,每个文件都有一个唯一的文件 ID。这个文件 ID 被用作工作节点选择算法的关键,用于决定哪个工作节点负责缓存该文件的元数据和数据。客户端也实现了同样的算法,因此客户端可以知道应向哪个工作节点请求缓存的文件。无论文件大小如何,工作节点都会将整个文件进行缓存。在读取文件时,无论客户端要读取文件的哪一部分,都会始终访问同一个工作节点。
当存储在 Alluxio 中的文件相对于工作节点缓存容量来说属于小到中等大小时,这种机制运行良好。工作节点可以轻松处理大量这种体积不大的文件,并且工作节点选择算法能够较为均衡地将文件分布到各个工作节点上。然而,对于那些文件大小接近单个工作节点缓存容量的超大文件来说,高效缓存这些文件会变得越来越困难。如果多个客户端同时请求同一个文件,那么单个工作节点就可能容易过载,导致整体读取性能下降。
文件分段是 Alluxio 的一项功能,它允许将一个超大文件拆分成多个段,并分别缓存在多个工作节点上。段的大小可由管理员进行配置,通常远小于整个文件的大小。文件的各个段可以由多个工作节点高效地提供服务,从而减少工作节点负载不均的问题。
以下使用场景可能会从文件分段中受益:
* 在 Alluxio 缓存中存储超大文件,这些文件大于或接近单个工作节点的缓存容量;
* 对读取性能要求较高的应用场景,这类应用可以从多个工作节点共同提供同一文件服务中受益。
**文件分段的工作原理(How File Segmentation Works)**
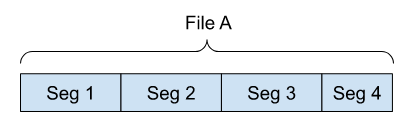
一个文件的分段是通过文件 ID 和其在文件中的索引来定义的,文件可以被看作是一个按顺序排列的段列表:
 段 ID 是一个由文件 ID 和段索引组成的二元组,定义如下:
```
Segment ID := (fileId, segmentIndex)
```
当客户端需要定位一个被分段的文件的多个部分时,会使用段 ID(而不是文件 ID)作为工作节点选择算法的键值。\
读取一个被分段的文件可以被拆解为按顺序读取各个段。
以下是一个包含 4 个段的文件示例:
段 ID 是一个由文件 ID 和段索引组成的二元组,定义如下:
```
Segment ID := (fileId, segmentIndex)
```
当客户端需要定位一个被分段的文件的多个部分时,会使用段 ID(而不是文件 ID)作为工作节点选择算法的键值。\
读取一个被分段的文件可以被拆解为按顺序读取各个段。
以下是一个包含 4 个段的文件示例:
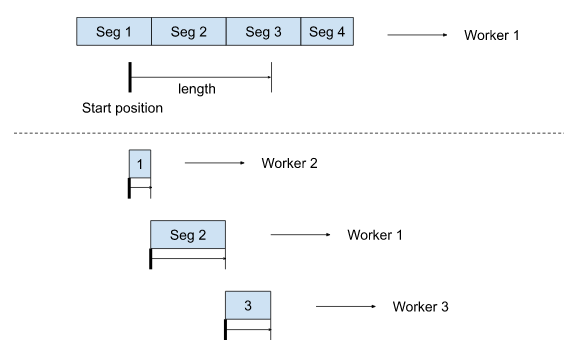 如果一次未分段的读取请求跨越了 3 个段的范围,那么它会被拆分成对这 3 个段的独立读取请求,\
每个段的读取将由不同的工作节点来提供服务。
目前,文件分段功能存在一些限制:
* 客户端直接在 Alluxio 中创建并写入的文件无法被分段;
* 段大小是在整个集群范围内统一设定的,所有节点必须使用相同的段大小,不能按文件单独设定。
#### 启用文件分段
| 配置项 | 推荐值 | 描述 |
| ---------------------------------------- | ------- | --------------- |
| `alluxio.dora.file.segment.read.enabled` | true | 设置为True从而启动文件分段 |
| `alluxio.dora.file.segment.size` | (取决于场景) | 分段的大小,默认为1GB |
* 将参数 `alluxio.dora.file.segment.read.enabled` 设置为 `true`;
* 设置参数 `alluxio.dora.file.segment.size` 为所需的分段大小;该值必须在所有节点上保持一致。
如何确定最佳的分段大小,可以参考以下因素:
* 不同的段通常会被映射到不同的工作节点上;当客户端顺序读取文件时,需要在不同的工作节点之间切换以读取不同的分段。如果段的大小太小,客户端会频繁地在多个工作节点之间切换,导致网络带宽利用率不高;
* 每个段的数据会完整地存储在一个工作节点上;
* 如果段的大小太大,可能会导致缓存分布不均,部分工作节点的缓存会过载,而其他节点空闲。
最佳的分段大小应在性能和缓存数据均衡分布之间取得平衡。\
常见的分段大小范围为几个 GB 到几十个 GB。
## AI 模型加载
Alluxio 针对模型加载效率进行了优化。
在典型的模型加载流程中,用户会将训练好的模型上传到底层存储系统(UFS),并使用 Alluxio 作为缓存层。这些模型随后通过 Alluxio Fuse 本地加载,供在线服务或推理系统使用。在这一过程中,Alluxio 作为缓存中间层,大幅提升了模型加载速度,并减轻了底层存储系统的压力。
由于单个 Alluxio Fuse 节点可能会同时处理多个模型的读取请求(例如,多个在线服务同时加载模型文件),这会带来显著的并发访问压力和流量峰值。模型文件通常体积较大,传统文件系统在处理高频并发读取时往往表现不佳。因此,引入 Alluxio 作为缓存层,是更适合模型分发场景的解决方案。
Alluxio 提升模型加载性能的主要方式是客户端预取。在大多数情况下,默认配置的预取机制已足够使用。
此外,当多个并发读取请求通过同一个 Alluxio Fuse 实例访问同一个模型文件时,增强的预取逻辑可以将加载性能提升最多达 3 倍。\
你可以通过以下配置项启用该功能:
```properties
alluxio.user.position.reader.streaming.async.prefetch.by.file.enabled=true
alluxio.user.position.reader.streaming.async.prefetch.shared.cache.enabled=true
```
如果一次未分段的读取请求跨越了 3 个段的范围,那么它会被拆分成对这 3 个段的独立读取请求,\
每个段的读取将由不同的工作节点来提供服务。
目前,文件分段功能存在一些限制:
* 客户端直接在 Alluxio 中创建并写入的文件无法被分段;
* 段大小是在整个集群范围内统一设定的,所有节点必须使用相同的段大小,不能按文件单独设定。
#### 启用文件分段
| 配置项 | 推荐值 | 描述 |
| ---------------------------------------- | ------- | --------------- |
| `alluxio.dora.file.segment.read.enabled` | true | 设置为True从而启动文件分段 |
| `alluxio.dora.file.segment.size` | (取决于场景) | 分段的大小,默认为1GB |
* 将参数 `alluxio.dora.file.segment.read.enabled` 设置为 `true`;
* 设置参数 `alluxio.dora.file.segment.size` 为所需的分段大小;该值必须在所有节点上保持一致。
如何确定最佳的分段大小,可以参考以下因素:
* 不同的段通常会被映射到不同的工作节点上;当客户端顺序读取文件时,需要在不同的工作节点之间切换以读取不同的分段。如果段的大小太小,客户端会频繁地在多个工作节点之间切换,导致网络带宽利用率不高;
* 每个段的数据会完整地存储在一个工作节点上;
* 如果段的大小太大,可能会导致缓存分布不均,部分工作节点的缓存会过载,而其他节点空闲。
最佳的分段大小应在性能和缓存数据均衡分布之间取得平衡。\
常见的分段大小范围为几个 GB 到几十个 GB。
## AI 模型加载
Alluxio 针对模型加载效率进行了优化。
在典型的模型加载流程中,用户会将训练好的模型上传到底层存储系统(UFS),并使用 Alluxio 作为缓存层。这些模型随后通过 Alluxio Fuse 本地加载,供在线服务或推理系统使用。在这一过程中,Alluxio 作为缓存中间层,大幅提升了模型加载速度,并减轻了底层存储系统的压力。
由于单个 Alluxio Fuse 节点可能会同时处理多个模型的读取请求(例如,多个在线服务同时加载模型文件),这会带来显著的并发访问压力和流量峰值。模型文件通常体积较大,传统文件系统在处理高频并发读取时往往表现不佳。因此,引入 Alluxio 作为缓存层,是更适合模型分发场景的解决方案。
Alluxio 提升模型加载性能的主要方式是客户端预取。在大多数情况下,默认配置的预取机制已足够使用。
此外,当多个并发读取请求通过同一个 Alluxio Fuse 实例访问同一个模型文件时,增强的预取逻辑可以将加载性能提升最多达 3 倍。\
你可以通过以下配置项启用该功能:
```properties
alluxio.user.position.reader.streaming.async.prefetch.by.file.enabled=true
alluxio.user.position.reader.streaming.async.prefetch.shared.cache.enabled=true
```